|
Multi-view Stereopsis from
Virtual Cameras
by
Dao Lam and
Ruizhi Hong
Introduction
In [1], we
proposed a new method for 3D modeling that uses multiple virtual views from a
single stereo pair. Our approach, while it is multi-view based, it does not
require a large number of calibrated cameras positioned around the object.
Instead, our method only requires a single pair of calibrated cameras and a
on-the-fly motion detection algorithm that estimates the position of virtual
cameras as the object moves with respect to the cameras. Besides its much lower
cost, and despite the much simpler setup, the 3D models created using this
approach are highly comparable to the original PMVS, while maintaining the same
computational efficiency. Also, as the original PMVS, our method works well on
various objects, including human faces, as we demonstrated in [1] and briefly
present below.
|
|
 |
|
(a) |
(b) |
|
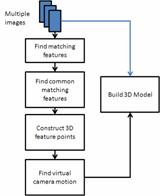
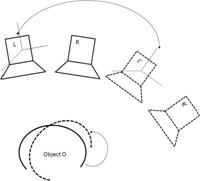
Figure 1: (a)
Proposed Framework for Virtual Multi-View 3D Modeling, (b) Real and
Virtual Cameras: L and R are real cameras; L’ and R’ are estimated
poses of two virtual cameras due to the motion of the object O |
Proposed Framework
Our framework
for 3D object modeling consists of six majors steps. Figure 1a depicts such
steps, which are: 1) Multiple pairs of stereo images are captured by 2
calibrated cameras while the object moves freely with respect to the cameras; 2)
A SIFT-based feature extraction algorithm establishes the correspondence
between various points on every stereo pair sampled; 3) The intersection between
the sets of points from two consecutive pairs of images is determined. That is,
common feature points present in both the left-right image pair at camera-object
position i and the subsequent left-right image pair at camera-object
position i+1 are identified; 4) The 3D coordinates of every point in the
intersection above is calculated; 5) The transformation between camera-object
poses are estimated using the 3D coordinates of the intersection; and 6) The
previous transformations are used to create virtual poses of the camera (Figure
1b) and fed into a patched-base multi-view software to construct the 3D model of
the object.
Results
Figure 2:
Quantitative and Qualitative Results obtained using human body and two objects:
(a) and (b) shows the 3D model of a face using respectively 16 and 70
low-resolution images; (c) three views of the 3D model created for the human
upper body also using low-resolution images; (d) and (f) shows the images of the
angel and bunny used for testing; (e) and (g) show the 3D model created using
higher-resolution cameras.
Table 1: Accuracy of
the proposed method for 3D Modeling
 |
3D Model created using Virtual Cameras
(click on the image to play the video) |
References
-
Lam, D., Hong, R, and DeSouza, G. N., "3D Human Modeling using
Virtual Multi-View Stereopsis and Motion Estimation", in Proceedings of the
2009 IEEE International Conference on Robotic System (IROS), pp. 4294-4299, Oct./09
-
Park J., DeSouza G.N.,
"
Photorealistic Modeling of Three Dimensional Objects Using Range
and Reflectance Data",
in Innovations in Machine Intelligence and Robot Perception ,
Edited by: S. Patnaik, L.C. Jain, G. Tzafestas and V. Bannore,
© Springer-Verlag (2005).
|







